

In this example, we’ll forecast the volatility of the S&P 500 and several publicly traded companies using GARCH and ARCH models
Prerequisites This tutorial assumes basic familiarity with StatsForecast. For a minimal example visit the Quick Start
Introduction
The Generalized Autoregressive Conditional Heteroskedasticity (GARCH) model is used for time series that exhibit non-constant volatility over time. Here volatility refers to the conditional standard deviation. The GARCH(p,q) model is given by where is independent and identically distributed with zero mean and unit variance, and evolves according to The coefficients in the equation above must satisfy the following conditions:- , for all , and for all
- . Here it is assumed that for and for .
- Install libraries
- Load and explore the data
- Train models
- Perform time series cross-validation
- Evaluate results
- Forecast volatility
Tip You can use Colab to run this Notebook interactively
Install libraries
We assume that you have StatsForecast already installed. If not, check this guide for instructions on how to install StatsForecast Install the necessary packages usingpip install statsforecast
Load and explore the data
In this tutorial, we’ll use the last 5 years of prices from the S&P 500 and several publicly traded companies. The data can be downloaded from Yahoo! Finance using yfinance. To install it, usepip install yfinance.
pandas to deal with the dataframes.
The data downloaded includes different prices. We’ll use the adjusted
closing
price,
which is the closing price after accounting for any corporate actions
like stock splits or dividend distributions. It is also the price that
is used to examine historical returns.
Notice that the dataframe that
yfinance returns has a
MultiIndex,
so we need to select both the adjusted price and the tickers.
The input to StatsForecast is a dataframe in long
format with
three columns:
unique_id, ds and y:
unique_id: (string, int or category) A unique identifier for the series.ds: (datestamp or int) A datestamp in format YYYY-MM-DD or YYYY-MM-DD HH:MM:SS or an integer indexing time.y: (numeric) The measurement we wish to forecast.
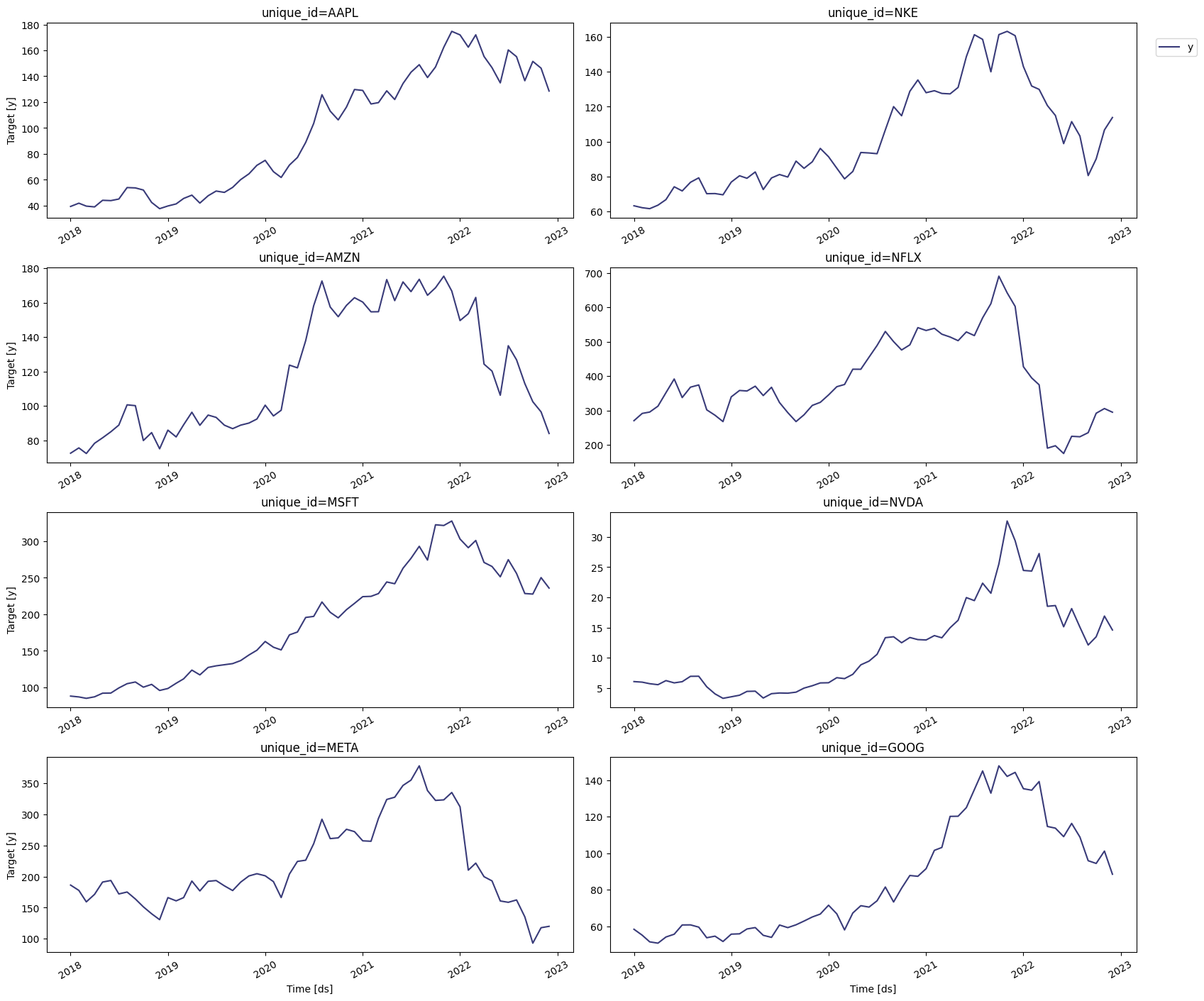
price.
We can plot this series using the
plot method of the StatsForecast
class.
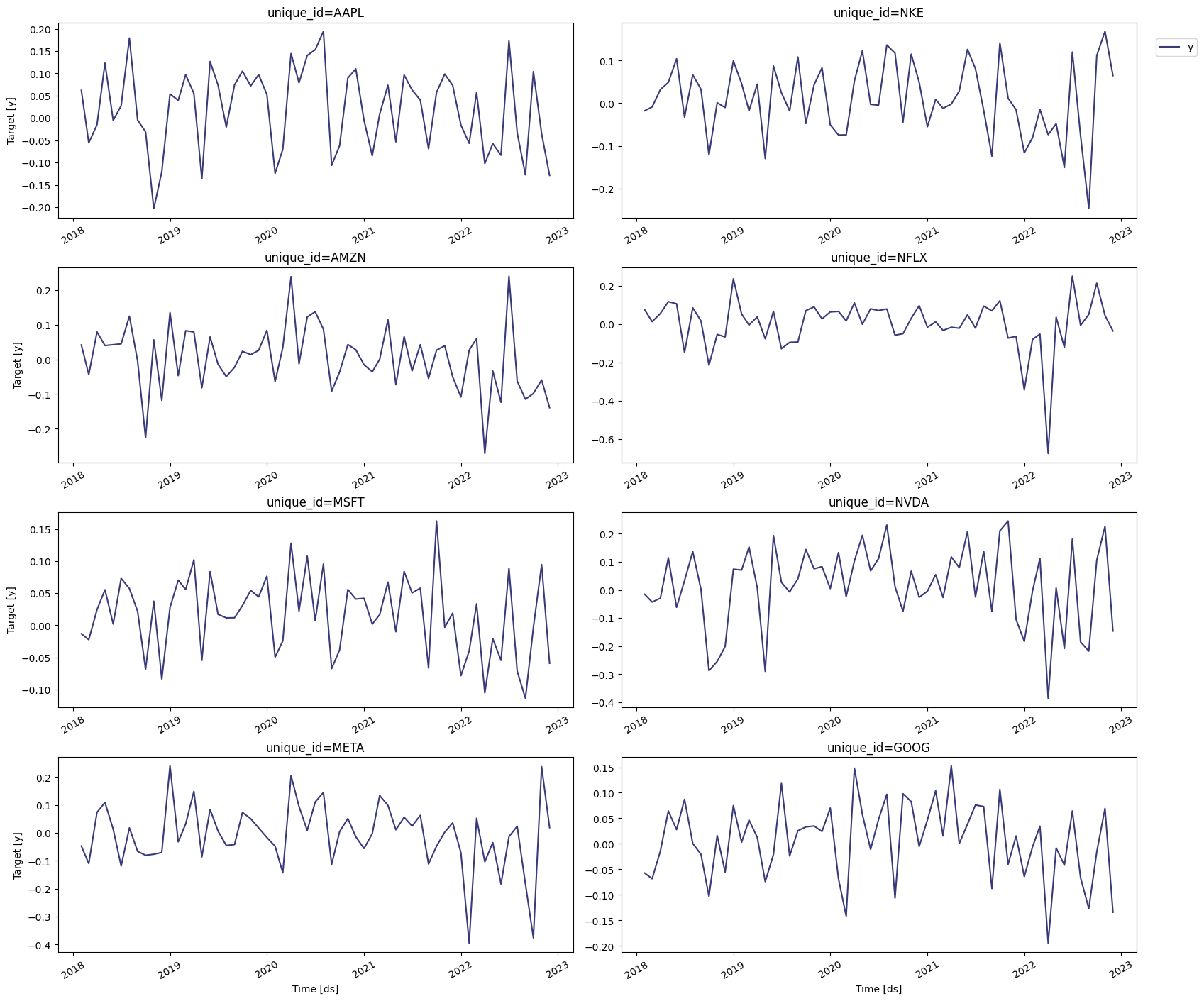
numpy.
Warning
If the order of the data is very small (say ),
scipy.optimize.minimize might not terminate successfully. In this
case, rescale the data and then generate the GARCH or ARCH model.
Train models
We first need to import the GARCH and the ARCH models fromstatsforecast.models, and then we need to fit them by instantiating a
new StatsForecast object. Notice that we’ll be using different values of
and . In the next section, we’ll determine which ones produce the
most accurate model using cross-validation. We’ll also import the
Naive model since we’ll use it as a
baseline.
df: The dataframe with the training data.models: The list of models defined in the previous step.freq: A string indicating the frequency of the data. Here we’ll use MS, which correspond to the start of the month. You can see the list of panda’s available frequencies here.n_jobs: An integer that indicates the number of jobs used in parallel processing. Use -1 to select all cores.
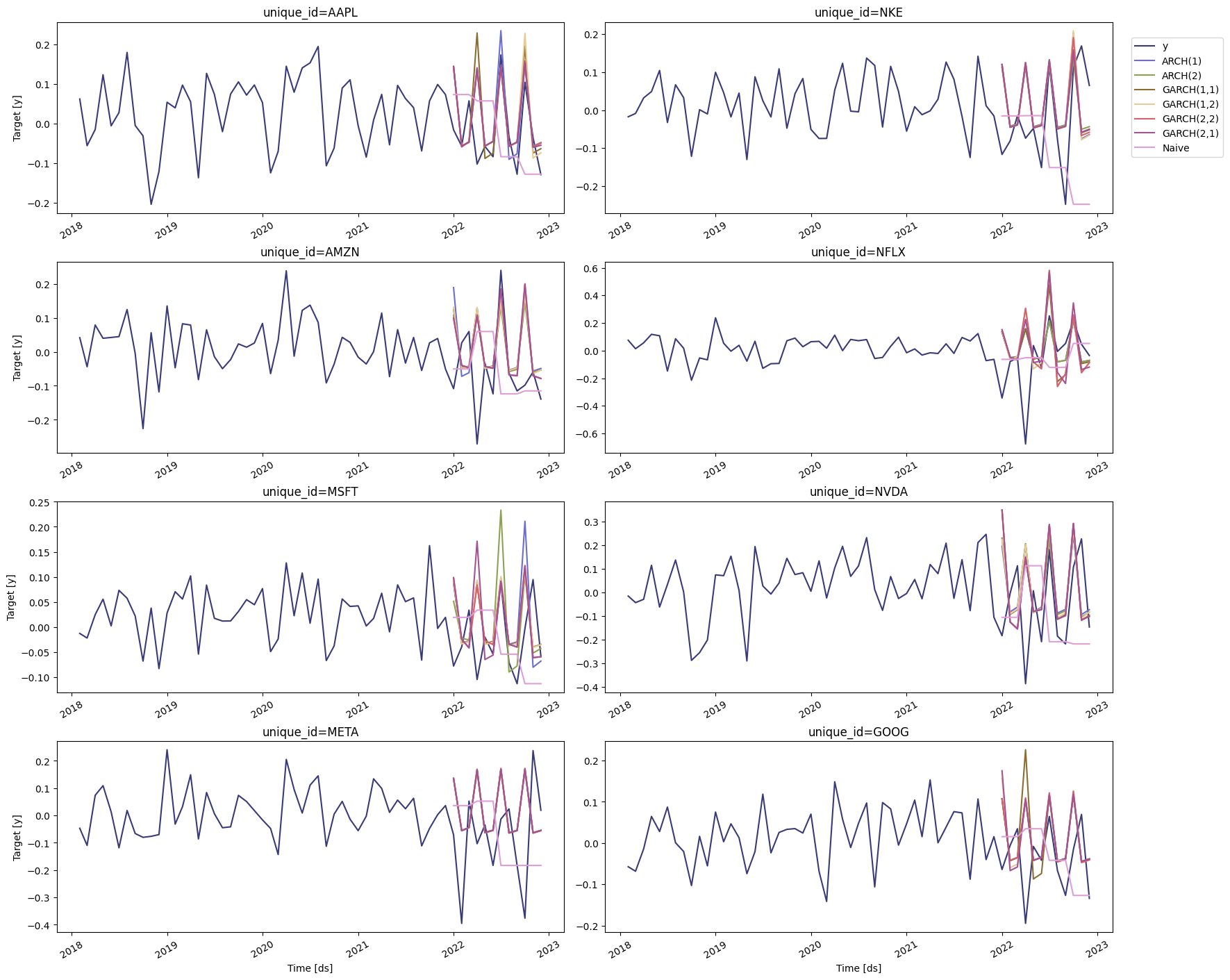
Perform time series cross-validation
Time series cross-validation is a method for evaluating how a model would have performed in the past. It works by defining a sliding window across the historical data and predicting the period following it. Here we’ll use StatsForecast’scross-validation method to determine the
most accurate model for the S&P 500 and the companies selected.
This method takes the following arguments:
df: The dataframe with the training data.h(int): represents the h steps into the future that will be forecasted.step_size(int): step size between each window, meaning how often do you want to run the forecasting process.n_windows(int): number of windows used for cross-validation, meaning the number of forecasting processes in the past you want to evaluate.
cv_df object is a dataframe with the following columns:
unique_id: series identifier.ds: datestamp or temporal indexcutoff: the last datestamp or temporal index for then_windows.y: true value"model": columns with the model’s name and fitted value.
Evaluate results
To compute the accuracy of the forecasts, we’ll use the mean average error (mae), which is the sum of the absolute errors divided by the number of forecasts.Forecast volatility
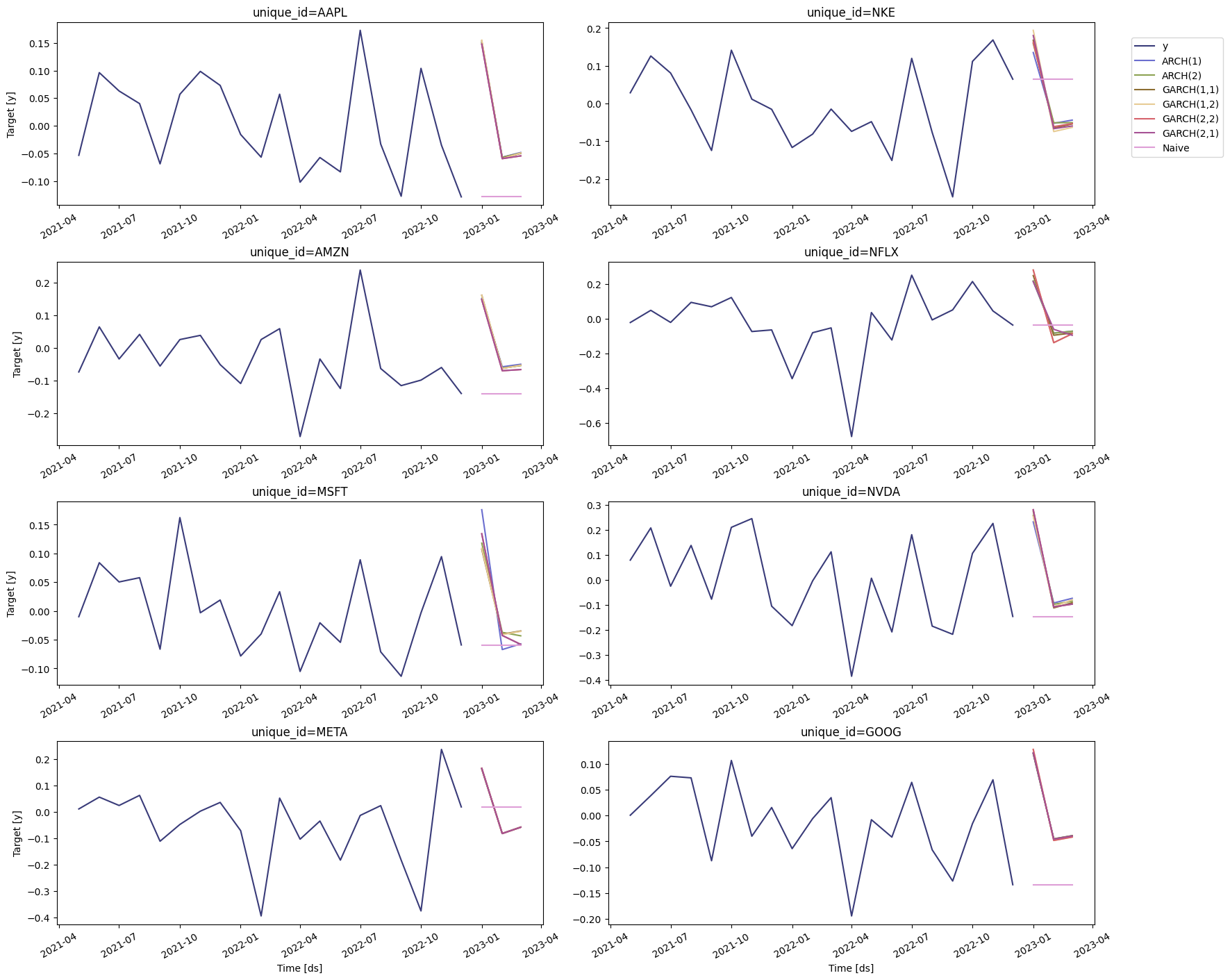
We can now generate a forecast for the next quarter. To do this, we’ll use theforecast method, which requires the following arguments:
h: (int) The forecasting horizon.level: (list[float]) The confidence levels of the prediction intervalsfitted: (bool = False) Returns insample predictions.
With the results of the previous section, we can choose the best model
for the S&P 500 and the companies selected. Some of the plots are shown
below. Notice that we’re using some additional arguments in the
plot
method:
level: (list[int]) The confidence levels for the prediction intervals (this was already defined).unique_ids: (list[str, int or category]) The ids to plot.models: (list(str)). The model to plot. In this case, is the model selected by cross-validation.
References
- Engle, R. F. (1982). Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation. Econometrica: Journal of the econometric society, 987-1007.
- Bollerslev, T. (1986). Generalized autoregressive conditional heteroskedasticity. Journal of econometrics, 31(3), 307-327.
- Hamilton, J. D. (1994). Time series analysis. Princeton university press.
- Tsay, R. S. (2005). Analysis of financial time series. John wiley & sons.